Selected Publications
Full lists of CVL members' publications are available on their personal pages. This page highlights selected papers, giving a little more detail. Follow the links for further details and the full articles.
A Functional Regression approach to Facial Landmark Tracking
E. Sánchez-Lozano, G. Tzimiropoulos, B. Martinez, F. De la Torre and M. Valstar. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017
Linear regression is a fundamental building block in many face detection and tracking algorithms, typically used to predict shape displacements from image features through a linear mapping. This paper presents a Functional Regression solution to the least squares problem, which we coin Continuous Regression, resulting in the first real-time incremental face tracker. Contrary to prior work in Functional Regression, in which B-splines or Fourier series were used, we propose to approximate the input space by its first-order Taylor expansion, yielding a closed-form solution for the continuous domain of displacements. We then extend the continuous least squares problem to correlated variables, and demonstrate the generalisation of our approach. We incorporate Continuous Regression into the cascaded regression framework, and show its computational benefits for both training and testing. We then present a fast approach for incremental learning within Cascaded Continuous Regression, coined iCCR, and show that its complexity allows real-time face tracking, being 20 times faster than the state of the art. To the best of our knowledge, this is the first incremental face tracker that is shown to operate in real-time. We show that iCCR achieves state-of-the-art performance on the 300-VW dataset, the most recent, large-scale benchmark for face tracking.
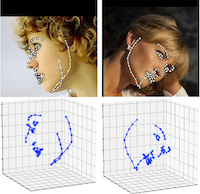
Large Pose 3D Face Reconstruction from a Single Image via Direct Volumetric CNN Regression
Aaron S. Jackson, Adrian Bulat, Vasileios Argyriou and Georgios Tzimiropoulos, ICCV 2017
3D face reconstruction is a fundamental Computer Vision problem of extraordinary difficulty. Current systems often assume the availability of multiple facial images as input, and must address a number of methodological challenges such as establishing dense correspondences across large facial poses, expressions, and non-uniform illumination. In this work, we propose to address many of these limitations by training a Convolutional Neural Network (CNN) on an appropriate dataset consisting of 2D images and 3D facial models or scans. Our CNN can reconstruct the entire 3D facial geometry with just a single 2D facial image, and without accurate alignment or establishing dense correspondence between images.
Find out more
Binarized Convolutional Landmark Localizers for Human Pose Estimation and Face Alignment with Limited Resources,
A. Bulat and G. Tzimiropoulos, ICCV 2017
Our goal is to design architectures that retain the groundbreaking performance of CNNs for landmark localization and at the same time are lightweight, compact and suitable for applications with limited computational resources. To this end, we propose a novel hierarchical, parallel and multi-scale residual architecture specifically designed for binarized CNNs that yields large performance improvement over the standard bottleneck block while having the same number of parameters, thus bridging the gap between the original network and its binarized counterpart. We present results for experiments on the most challenging datasets for human pose estimation and face alignment, reporting in many cases state-of-the-art performance.
Find out more
How far are we from solving the 2D & 3D Face Alignment problem? (and a dataset of 230,000 3D facial landmarks)
A. Bulat and G. Tzimiropoulos, ICCV 2017
This paper investigates how far a very deep neural network is from attaining close to saturating performance on existing 2D and 3D face alignment datasets. To this end, (a) we construct, for the first time, a very strong baseline by combining a state-of-the-art architecture for landmark localization with a state-of-the-art residual block, train it on a very large yet synthetically expanded 2D facial landmark dataset and finally evaluate it on all other 2D facial landmark datasets. (b) We create a guided by 2D landmarks network which converts 2D landmark annotations to 3D and unifies all existing datasets, leading to the creation of LS3D-W, the largest and most challenging 3D facial landmark dataset to date (~230,000 images). (c) We show that both 2D and 3D face alignment networks achieve performance of remarkable accuracy which is probably close to saturating the datasets used.
Find out more

SuRVoS: Super-Region Volume Segmentation Workbench
Imanol Luengo, Michele C. Darrow, Matthew C. Spink, Ying Sun, Wei Dai, Cynthia Y. He, Wah Chiu, Tony Pridmore, Alun W. Ashton, Elizabeth M.H. Duke, Mark Basham, and Andrew P. French, J Struct Biol. 2017
Segmentation of biological volumes is a crucial step needed to fully analyse their scientific content. Current methods usually require a large amount of manually-produced training data to deliver a high-quality segmentation. However, the complex appearance of cellular features, high variance from one sample to another, and the time-consuming work of manually labelling complete volumes, makes training data very scarce. We present a new workbench named SuRVoS (Super-Region Volume Segmentation). Within this software, a volume to be segmented is first partitioned into hierarchical segmentation layers (named Super-Regions) and is then interactively segmented with the user's knowledge input in the form of training annotations. SuRVoS first learns from and then extends user inputs to the rest of the volume, while using Super-Regions for quicker and easier segmentation than when using a voxel grid.
Human pose estimation via Convolutional Part Heatmap Regression
A. Bulat and G. Tzimiropoulos, ECCV 2016
This paper is on human pose estimation using Convolutional Neural Networks. Our main contribution is a CNN cascaded architecture specifically designed for learning part relationships and spatial context, and robustly inferring pose even for the case of severe part occlusions. To this end, we propose a detection-followed-by-regression CNN cascade. The first part of our cascade outputs part detection heatmaps and the second part performs regression on these heatmaps. The benefits of the proposed architecture are multi-fold: It guides the network where to focus in the image and effectively encodes part constraints and context. Our method achieves top performance on the MPII and LSP data sets.
Find out more